
 AI+安全
AI+安全 數據安全
數據安全 數據基礎設施
數據基礎設施 態勢感知
態勢感知 云安全
云安全 基礎安全
基礎安全 終端安全
終端安全 商用密碼
商用密碼 軟件供應鏈安全
軟件供應鏈安全 網絡空間靶場
網絡空間靶場 工業互聯網安全
工業互聯網安全 物聯網安全
物聯網安全






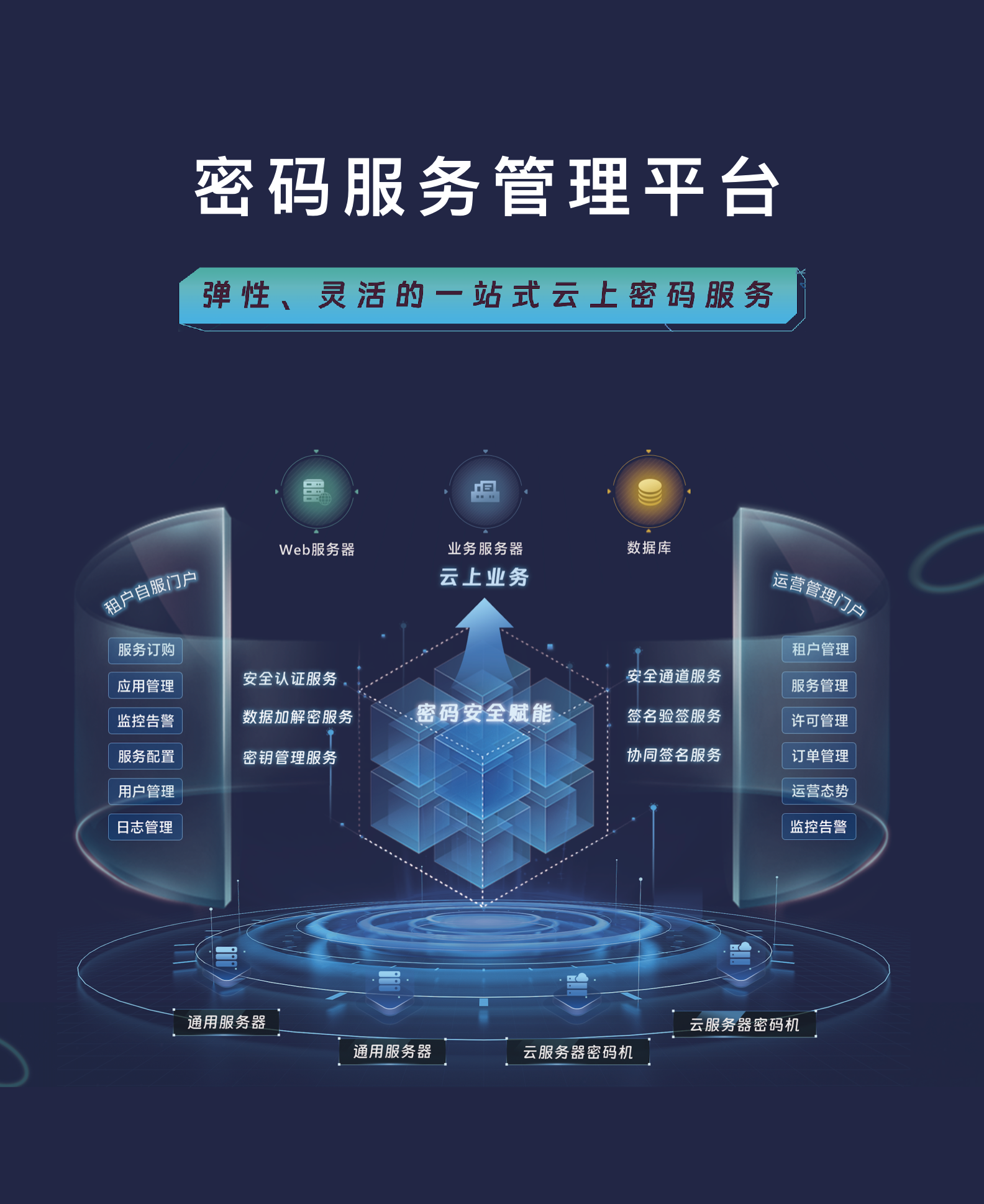



 安全托管服務
安全托管服務 運營管理服務
運營管理服務






公司
Security&AI持續深耕,安恒信息研究成果獲國際學術會議認可
近日,安恒信息中央研究院安通鑒博士帶領的AI安全團隊針對網絡攻防場景的基于深度學習的webshell檢測的研究成果“Deep Learning Based Webshell Detection Coping with Long Text and Lexical Ambiguity”,被高等級國際學術會議ICICS International Conference on Information and Communications Security 2022(隸屬中國計算機學會推薦國際學術會議和期刊目錄)收錄并在線發表。

該研究的唯一完成單位為安恒信息,是安恒信息中央研究院在信息安全和人工智能領域交叉創新和持續深耕的成果。ICICS是網絡信息安全領域的老牌學術會議,至今已經舉辦24屆。該國際學術會議錄用比例較低,每年僅有30篇左右的論文可以錄用,2022年的錄用比例為22.7%。安恒信息的論文經過5位專家審稿人2輪的同行審議(peer review),從全球164篇投稿論文中脫穎而出,被ICICS 2022成功錄用。

Webshell是一種可以讓攻擊者獲取主機權限的惡意腳本,攻擊者通過網站的漏洞上傳webshell后,可以持續的獲取主機的控制權,因此webshell的檢測在網絡攻防環境中具有重要意義。Webshell種類繁多,語法靈活,傳統基于規則的方法、基于啟發式的方法和基于機器學習的方法在webshell檢測中都有一定的局限性,導致誤報率和漏檢率較高,而深度學習的方法可以充分挖掘文本的上下文信息,但仍然面臨處理長文本時的低效和語義損失,以及在面對復雜語法時的一詞多義性問題。
長文本在webshell檢測領域是頻繁出現的,對已知webshell和正常樣本的代碼行數和token數統計,一半以上的webshell代碼token個數超過3400,代碼行數超過49行,而一半以上的正常代碼token個數超過1000,代碼行數超過70. 所以需要合適的方法在保留核心語義的同時去除冗余信息。
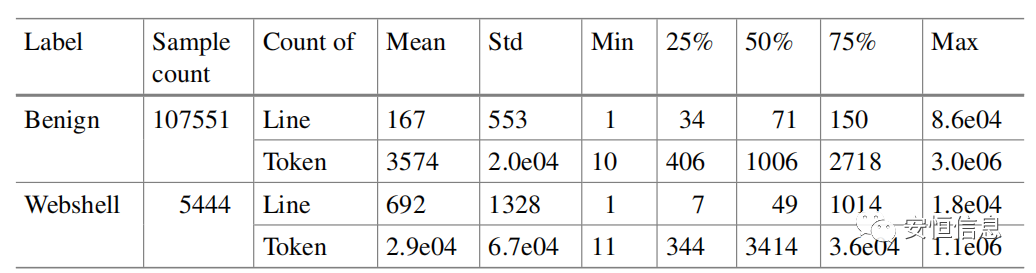
文本長度統計信息
一詞多義在文本處理中是比較棘手的問題,就像“蘋果”在不同的上下文中可以呈現水果的語義也可以呈現手機的語義。一詞多義在webshell檢測中表現為同一個名稱的token,有時呈現變量語義,有時呈現函數語義,有時呈現類成員語義等(如下圖中的‘status’分別呈現了成員語義和變量語義)。所以需要在不同的上下文中給token以不同的向量表示。
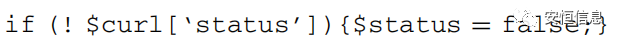
面對長文本,論文采用了textrank模型來篩選重要語義信息,該算法可以通過相似度加權迭代的方式對代碼進行重要性排序。
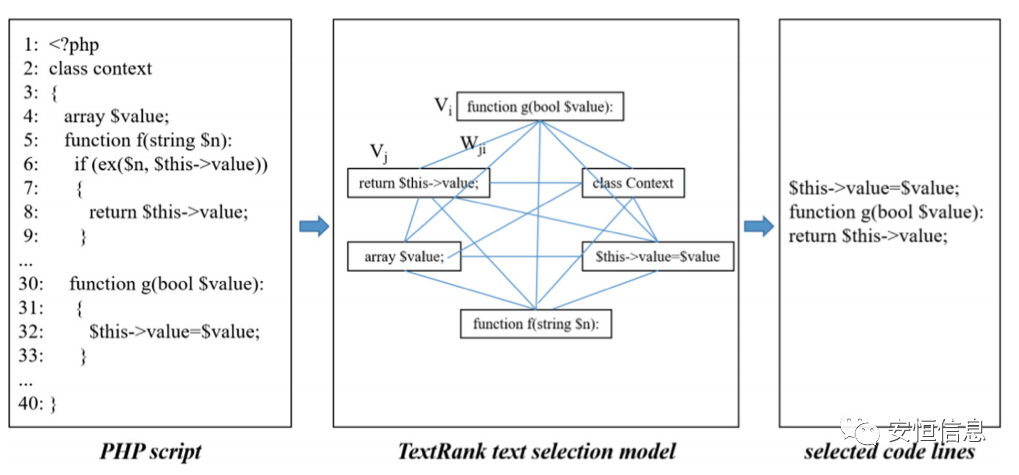
Textrank模塊架構
面對一詞多義問題,論文采用codebert方法學習token的上下文信息,在不同的語境下給token以不同的變量表示。
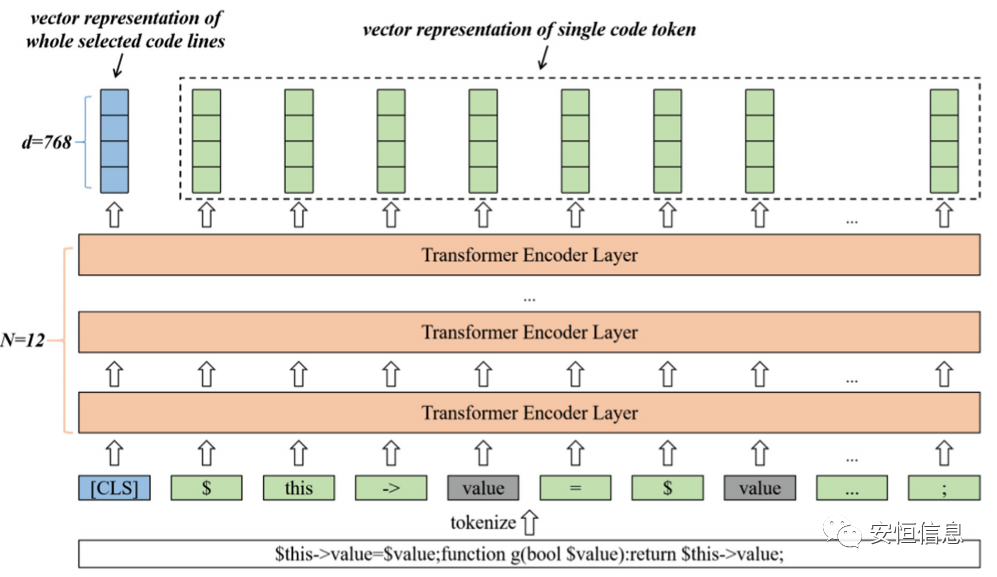
Codebert模塊架構
結合textcnn結構的分類head,模型的整體為一個two-stage的架構,loss在textcnn和codebert中進行反向傳播,而textrank模型不參與誤差的反向傳播。
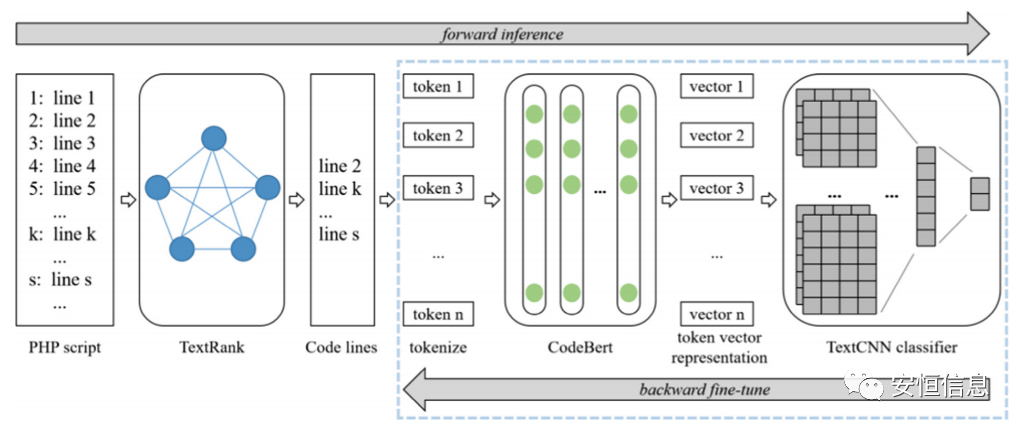
模型整體架構
模型經過數十epoch的訓練,在數十萬樣本的測試中,其綜合表現F1-score超過了3種webshell檢測工具和3種基于深度學習的webshell檢測模型。在達到較高檢出率的同時,也保證了較低的誤報率。
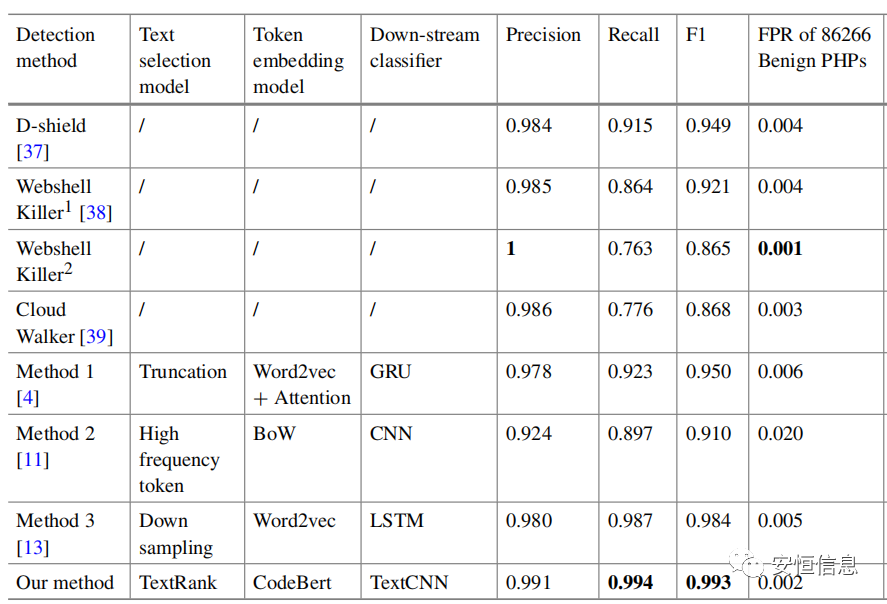
部分實驗結果

掃碼可下載原文






